Pipeline을 사용하면 문제점들이 생긴다. 그 문제점들을 Pipeline Hazard라고 한다.
💻 Type of hazards
Pipelined Hazard에는 총 3가지가 있다.
1. Structural Hazard
2. Data Hazard
3. control Hazard
여기서 Structural Hazards에 대해서 간단하게 짚고 넘어가보자.
이 hazard는 하드웨어가 같은 resource를 서로 쓰려고 하는 경우에 발생한다. 한 clock에 5개의 인스터럭션이 들어와있는데, 그 중 2개가 메모리를 쓰려고 한다면 structural Hazard가 발생한다.
MEM 단계에서도, 메모리에 access를 하고 있고, IF 단계에서도 메모리에 access를 하고있다.
서로 다른 명령어의 두 단계가 같은 메모리에 접근을 하려고 하기떄문에 이경우에 발생한다.
해결법: 추가적인 메모리를 배치하면 해결이된다.
💻 Data Hazards
Data Hazard는 data dependency가 있을때 발생하는 hazard이다.

instruction으로
add x1,x2,x3;
sub x4,x1,x5
이렇게 들어왔다고 가정해보자.
여기서 add instruction의 rd는 x1이다. 그 x1을 sub instruction은 rs1로 사용하고있다.
여기서 pipeline을 사용하여 차례차례 진행한다면 아직 add의 결과값이 들어가지도 않은 x1을 sub는 rs1으로 사용하게 될거다. 그러면 원하는 값을 사용하지 못한다.
그래서, 그림과같이 bubble을 사용하게 된다.
bubble을 채워서, sub instruction을 뒤로 늦추게 한다. 그래서 add 명령어가 WB까지 다 행한 뒤 그것을 sub명령어가 ID 해와서 수행하게 된다. 이렇게 되면 쓸 데없이 시간이 늦춰지게 된다. 그래서 Forwarding을 하여 이 data hazard를 해결한다.
💻 Forwarding

생각해보니, EX 단계까지 끝나면 원하는 값은 이미 도출되어 있다는 것을 알 수 있었다.
위에서 add x1,x2,x3의 EX에서 ALU의 Output은 sub instruction이 원하는 값이다. 그것을 EX의 input으로 떙겨온다.
이것을 Forwarding이라고한다.
data dependency가 있을 때, Forwarding을 쓰면 어떤 cycle도 낭비가 되지 않고 bubble도 사용되지 않는다.
💻 load-use data hazard
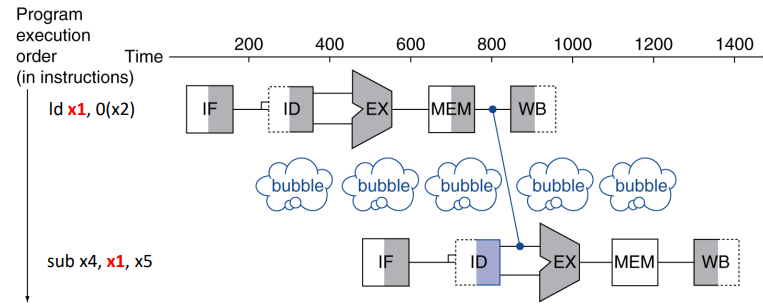
load-use data hazard는 data hazard의 일종으로, ld 뒤에 R-type이 오는 경우를 일컫는다.
ld는 원하는 값이 MEM 뒤에야 나온다.
우리는 data hazard를 뛰어넘기 위해, Forwarding을 사용하는데, 이 경우에는 Forwarding을 사용하더라도 bubble이 한번 들어갈 수 밖에 없다 이 경우엔 1cycle 손해를 본다.
이 조합이 얼마나 많냐에따라 성능이 달라진다.
💻 In code
load -use data hazard를 최대한 줄여야 성능이 좋아진다. 이럴때, code를 어떻게 짜냐에따라 이 횟수가 달라진다.
a=b+e;
c=b+f;
이 경우를 수행하고 싶다고 한다. 이때, 어셈블리어 코드를 보자.

왼쪽처럼 쓰인다면, load-use 경우가 2번이나 발생하며, 이때는 2cycle 손해 볼것이다.
이것을 ld를 앞으로 다빼고, add를 뒤로 빼면, 1cycle만 손해를 볼 수 있다.
이렇게 해서, load-use data hazard를 줄일수 있다.
'2-2 > 컴퓨터 구조' 카테고리의 다른 글
| [컴퓨터 구조] Direct- mapped Cache (0) | 2022.11.25 |
|---|---|
| [컴퓨터 구조] Cache (0) | 2022.11.25 |
| [컴퓨터 구조] Pipeline (0) | 2022.11.23 |
| [컴퓨터 구조] Type of Instructions (0) | 2022.10.11 |
| [컴퓨터 구조] 3. RISC-V Operands (1) | 2022.10.10 |



